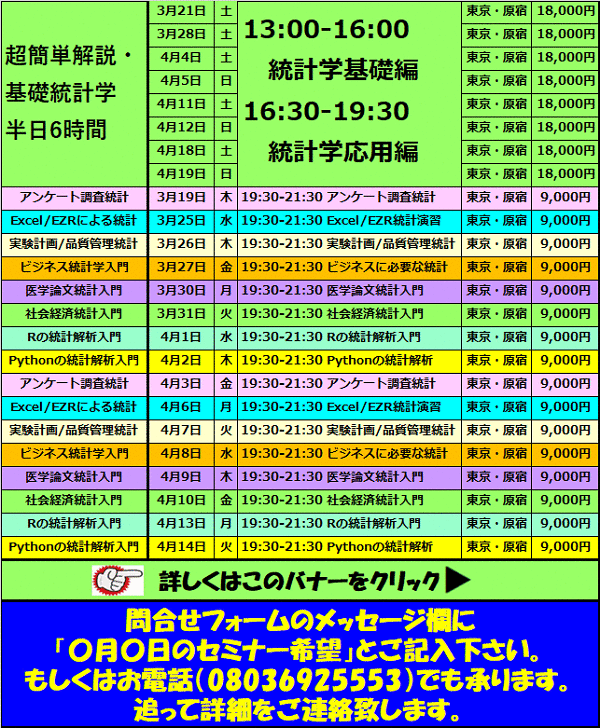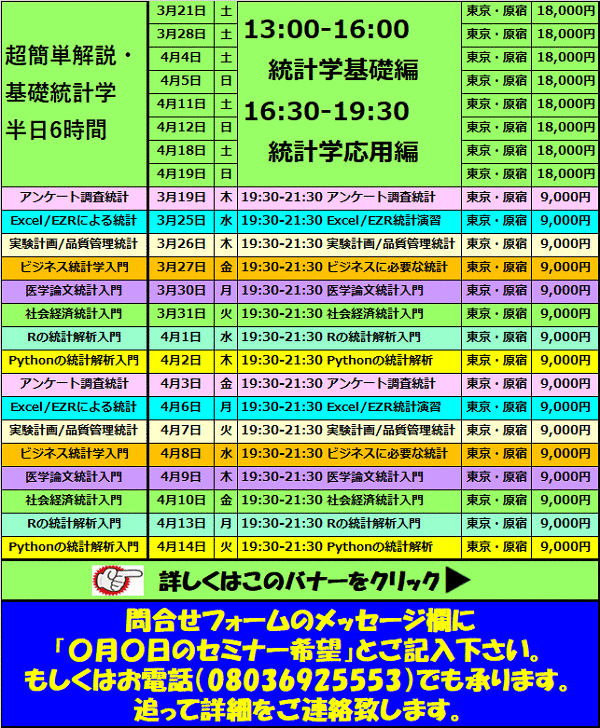
▼▼▼▼▼▼▼▼ ▼▼▼▼▼▼▼▼
お問合せはこちら セミナー詳細こちら
医療統計学:ビッグデータ
医療統計学、医療経済学、数学のつぼをたとえ話でわかりやすく解説
運営者の20年以上にわたる医療統計学のノウハウを満載
ビッグデータ
ビッグデータとは何か
ビッグデータとは何か。これについては、ビッグデータを「事業に役立つ知見を導出するためのデータ」とし、ビッグデータビジネスについて、「ビッグータを用いて社会・経済の問題解決や、業務の付加価値向上を行う、あるいは支援する事業」と目的的に定義している例があります。
ビッグデータは、どの程度のデータ規模かという量的側面だけでなく、どのようなデータから構成されるか、あるいはそのデータがどのように利用されるかという質的側面において、従来のシステムとは違いがあると考えられます。
まず、その量的側面については(何を「ビッグ」とするか)、「ビッグデータは、典型的なデータベースソフトウェアが把握し、蓄積し、運用し、分析できる能力を超えたサイズのデータを指します。
この定義は、意図的に主観的な定義であり、ビッグデータとされるためにどの程度大きいデータベースである必要があるかについて流動的な定義に立脚しています。
ビッグデータは、多くの部門において、数十テラバイトから数ペタバイト(a few dozen terabytes to multiple petabytes)の範囲に及ぶだろう。」との見方があります。ただし、ビッグデータについては、後に述べるように、目的面から量的側面を考えるべき点について、留意する必要があります。
次に、その質的側面についてみると、第一に、ビッグデータを構成するデータの出所が多様である点を特徴として挙げることができます。
現在既に活用が進んでいるウェブサービス分野では、オンラインショッピングサイトやブログサイトにおいて蓄積される購入履歴やエントリー履歴、ウェブ上の配信サイトで提供される音楽や動画等のマルチメディアデータ、ソーシャルメディアにおいて参加者が書き込むプロフィールやコメント等のソーシャルメディアデータがあります。
また、今後活用が期待される分野の例では、GPS、ICカードやRFIDにおいて検知される、位置、乗車履歴、温度等のセンサーデータ、CRM(Customer Relationship Management)システムにおいて管理されるダイレクトメールのデータや会員カードデータ等カスタマーデータといった様々な分野のデータが想定されており、さらに個々のデータのみならず、各データを連携させることでさらなる付加価値の創出も期待されるところです。
質的側面の2点目としては、ビッグデータは、その利用目的からその対象が画定できるものであり、その意味では、冒頭に掲げた定義例が有用です。ただし、その利用目的から特徴に着目する場合においても、データの利用者(ユーザー企業等)とそれを支援する者(ベンダー等)両者の観点からは異なっています。
データを利用する者の観点からビッグデータを捉える場合には、「事業に役立つ有用な知見」とは、「個別に、即時に、多面的な検討を踏まえた付加価値提供を行いたいというユーザー企業等のニーズを満たす知見」ということができ、それを導出する観点から求められる特徴としては、「高解像(事象を構成する個々の要素に分解し、把握・対応することを可能とするデータ)」、「高頻度(リアルタイムデータ等、取得・生成頻度の時間的な解像度が高いデータ)」、「多様性(各種センサーからのデータ等、非構造なものも含む多種多様なデータ)」の3点を挙げることができます。これらの特徴を満たすために、結果的に「多量」のデータが必要となリます。
他方、このようなデータ利用者を支援するサービスの提供者の観点からは、以上の「多量性」に加えて、同サービスが対応可能なデータの特徴として、「多源性(複数のデータソースにも対応可能)」、「高速度(ストリーミング処理が低いレイテンシーで対応可能)」、「多種別(構造化データに加え、非構造化データにも対応可能)」が求められることとなリます。
このように、ビッグデータの特徴としては、データの利用者やそれを支援する者それぞれにおける観点から異なっていますが、共通する特徴としては、多量性、多種性、リアルタイム性等が挙げられます。
ICTの進展により、このような特徴を伴った形でデータが生成・収集・蓄積等されることが可能・容易になってきており、異変の察知や近未来の予測等を通じ、利用者個々のニーズに即したサービスの提供、業務運営の効率化や新産業の創出等が可能となる点に、ビッグデータの活用の意義があるものと考えられます。
ビッグデータ(英: big data)とは、市販されているデータベース管理ツールや従来のデータ処理アプリケーションで処理することが困難なほど巨大で複雑な データ集合の集積物を表す用語です。その技術的な課題には収集、取捨選択、保管、検索、共有、転送、解析、可視化が含まれます。
大規模データ集合の傾向をつかむことは、関連データの1集合の分析から得られる付加的情報を、別の同じデータ量を持つ小規模データ集合と比較することにより行われ、「ビジネスの傾向の発見、研究の品質決定、疾病予防、 法的引用のリンク 、犯罪防止、リアルタイムの道路交通状況判断」との相関の発見が可能になります。
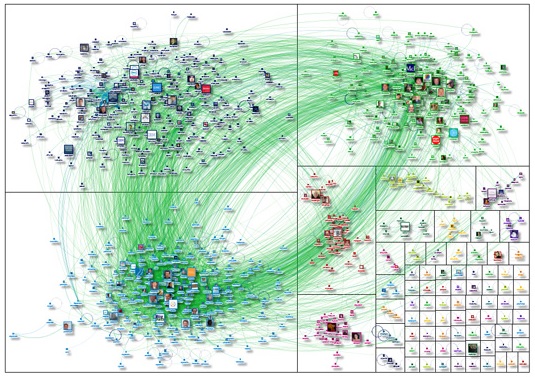
IBMによるWikipediaの可視化イメージ 大きさはテラバイトで、ウィキペディアのテキストおよび画像は、ビッグデータの典型的な例です。
2012年現在妥当な時間内に処理することが可能なデータ集合のサイズの制限は、エクサバイトのオーダーのデータです。科学者が大規模なデータ集合による制限に遭遇することは、しばしば発生し、その分野にはゲノミクス、気象学、コネクトミクス、複雑な物理シミュレーション、生物調査および環境調査が含まれます。同様の制限は インターネット検索、金融、ビジネスインフォマティクスにも影響を与えます。
データ集合が増加するのは、情報収集モバイル装置、空間センサー技術(リモートセンシング)、ソフトウェアログ、カメラ、マイクロフォン、無線ID読取機、ワイヤレス・センサー・ネットワークの普及も1つの原因です。全世界での1人当たりの情報容量は1980年代以降40か月ごとに倍増し、2012年現在1日あたり毎日250京(2.5×1018)バイトのデータが作成されました。大企業にとっての課題は、組織全体にまたがるビッグデータの主導権を誰が握るかということです。
ビッグデータは、大部分のリレーショナルデータベース管理システム、デスクトップ統計可視化パッケージでは処理が困難であり、その代わり、「数十台、数百台、ときには数千台ものサーバ上で動く大規模並列化ソフトウェア」が必要になります。
何を「ビッグデータ」と考えるかは、データ集合を管理する組織の能力と、扱うデータの領域において従来分析に用いられてきたアプリケーションの能力に依存します。数百ギガバイトのデータに初めて直面してデータ管理の選択肢について再検討を始めた組織もあります。また数十、数百テラバイトのデータになって初めて真剣に検討が必要になった組織もあります。
目次
1 定義
2 例
2.1 巨大科学
2.2 科学研究
2.3 政府
2.4 民間部門
2.5 国際的開発
3 マーケット
4 アーキテクチャー
5 テクノロジー
6 研究活動
7 批判
7.1 ビッグデータパラダイムへの批判
7.2 ビッグデータ実行の批判
§定義
ビッグデータは、通常、収集 取捨選択、管理、および許容される時間内にデータを処理するために一般的に使用されるソフトウェアツールの能力を超えたサイズのデータ集合を含んでいます。ビッグデータのサイズは、常に動いている目標値であり、単一のデータ集合内では、2012年現在数十テラバイトから数ペタバイトの範囲です。目標値は、従来のDBMS技術だけでなく、NoSQLのような新しいデータベースとその大量データ処理能力により動いています。この困難性により、「ビッグデータ」の新しいツールプラットフォームが、大量のデータの様々な側面を処理するために開発されています。
2001年の研究報告書と関連する講義では、METAグループ(現ガートナー )のアナリスト、ダグ・レイニーはデータ成長の課題とチャンスは3次元、すなわち、ボリューム(volume、データ量)、速度(velocity、入出力データの速度)、バラエティ(variety、データタイプとデータ源の範囲)であると定義しました。ガートナーは、現在業界の主役であるが、この「3V」モデルをビッグデータを述べるときに現在も使用しています。
2012年、ガートナーは、次のように、その定義を更新しました:「ビッグデータは、高ボリューム、高速度、高バラエティの情報資産のいずれか(あるいは全て)であり、新しい形の処理を必要とし、意思決定の高度化、見識の発見、プロセスの最適化に寄与する」 さらに新しいV、正確さ(veracity)がある組織により追加されました。
ガートナーの定義(3V)はまだ広く使用されているが、概念が成熟するにつれ、ビッグデータとビジネス・インテリジェンスの、データと利用について、確固とした違いが明らかになりました。
ビジネスインテリジェンスは、高密度データに要約統計を使用し、物事の計測や傾向を捉えます。
ビッグデータは、低密度データに誘導統計を使用し、巨大なボリュームにより(回帰性等の)法則を推論し、(推論による限界はあるが)予測可能性を生み出します。
§例
例としては、巨大科学、RFID、センサーネットワーク、ソーシャルネットワーク、ビッグソーシャルデータ分析 (ソーシャルデータ革命による)、インターネット文書、インターネット検索のインデックス作成、通話記録明細、天文学、大気科学、ゲノミクス、生物地球化学、生物学、他の複雑でしばしば学際的な科学研究、軍事偵察、新しい住宅購入者用の通勤時間予測、医療記録、写真アーカイブ、ビデオアーカイブ、大規模なeコマースがあります。
§巨大科学
大型ハドロン衝突型加速器では約1億5000万のセンサーが毎秒40万のデータを発生させます。毎秒ほぼ6億の衝突があります。ストリームからフィルタリングと、99.999%の繰り返し除去処理のあと、1秒あたり100の衝突が有用なデータとなります。
その結果、センサストリームデータの0.001%未満を処理して、すべての4つのLHC実験からのデータフローは複製前(2012年)に比較し1年に25ペタバイトを発生します。これは複製後約200ペタバイトになります。
全てのセンサデータがLHCで記録されるなら、データフローの処理は著しく困難になるでしょう。データフローは、複製前に、1年に1.5億ペタバイト、すなわち一日あたり約500 エクサバイトを超えてしまうでしょう。この数字は、一日あたり5垓(5×1020)バイトで、これは世界で結合されたすべての情報源を合計した数値の約200倍です。
§科学研究
スローン・デジタル・スカイサーベイ (SDSS)は2000年に天文データを収集し始めましたが、最初の数週間で天文学の歴史の中で収集したすべてのデータよりも、多くのデータを蓄積した。SDSSは、1晩約200GBの割合で継続して、140テラバイト以上の情報を集めています。SDSSの後継である、大型シノプティック・サーベイ望遠鏡は、2016年に運用開始後、同じ量のデータを5日おきに取得すると期待されています。
ヒトゲノム計画は当初その処理に10年かかりましたが、今では一週間も経たないうちに達成することができます。DNAシーケンサは、過去10年間でシーケンシングのコストを1万分の1に削減しました。これはムーアの法則の100倍に相当します。
計算機社会科学 Tobias Preis et al. はGoogle Trendsデータを使用し、高いGDPを持つ国のインターネットユーザは、過去よりも将来の情報を検索することを示しました。調査結果により、インターネット上の行動と現実世界の経済指標との間に関連性が存在することが示唆されました。
2010年に45の異なる国でインターネットユーザーによるGoogleのクエリのログを調べた結果によると、前年の検索のボリューム(2009年)と来年(2011年)の検索のボリュームを比較し、「将来期待指数」と呼んでおり、それぞれの国の1人当たりGDPと将来期待指数を比較し、将来についてより検索が多いGoogleユーザは高いGDPを持つ傾向があることが発見されました。
NASA気候シミュレーションセンター(NCCS)は32ペタバイトの気象観測、シミュレーションデータをDiscoverスーパーコンピューティングクラスタ上に格納しています。
Tobias Preisと共同研究者のHelen Susannah Moat、ユージン・スタンレーは、Google Trendsにより提供される検索ボリュームデータに基づく取引戦略を用いて、インターネット上の株価の動きを予測する方法を紹介しました。
金融に関連した98の用語のGoogle検索ボリュームの分析は''Scientific Reports''(英語: Scientific Reports) に掲載され、金融に関連した検索語は、金融市場の大きな損失より前に出ていることを示しました。
§政府
2012年、オバマ政権はビッグデータを政府が直面する重要問題への対処に利用できるかを探るため、ビッグ・データ・リサーチ・イニシアティブを発表しました。イニシアティブは、6つの部門にまたがって84の異なるビッグデータプログラムから構成されていました。
ビッグデータ分析は、 バラク・オバマの2012年の再選運動に大きな役割を果たしました。
米国連邦政府は、世界で10台の最も強力なスーパーコンピュータのうち6台を所有しています。
ユタ・データ・センターは、現在、米国 国家安全保障局(NSA)によって建築中のデータセンターです。建設後、施設は、インターネット上でNSAによって収集されたヨタバイトの情報を扱うことができるようになっています。
§民間部門
Amazon.comは、数百万のバックエンド業務を扱い、毎日、同時に50万以上のサードパーティ出品者からのクエリを処理します。Amazonの業務を支えるコア技術は、Linuxベースで、2005年の時点で、それぞれ7.8、18.5、24.7テラバイトの容量を持つ、世界で最大のLinuxの3つのデータベースを持っていました。
ウォルマートは1時間あたり百万以上の顧客トランザクションを処理し、2.5ペタバイト(2560テラバイト)のデータを保持するデータベースに取り込まれています。それはアメリカ議会図書館に所蔵されているすべての書籍の167倍の情報量です。
Facebookは、ユーザーからの500億枚の写真を処理しています。
FICOファルコンクレジットカード詐欺検知システムは、世界全体で21億アクティブなアカウントを保護しています。
全世界のビジネス・データの量は、すべての企業全体で、推計によると、1.2年ごとに倍増しています。
ウィンダミア不動産は約1億の匿名のGPS信号を使用し、新しく家を買う人に1日の異なった時間帯での通勤での運転時間を提供しています。
ソフトバンクは、月間約10億件(2014年3月現在)の携帯電話のログ情報を処理して、電波の接続率の改善に役立てています。
§国際的開発
ここ数十年で情報通信技術開発 (ICT4D)の有効利用の分野で研究が進み, ビッグ・データが国際開発に有用な貢献ができることが示唆されました。一方で、ビッグデータの出現により、医療、雇用、経済の生産性、犯罪や公衆安全、自然災害や資源管理などの重要な開発分野での意思決定を改善するための費用対効果の高い予測ができました。
また、ビッグデータの議論のすべてのよく知られた問題、例えば、プライバシー、相互運用性の課題、不完全アルゴリズムを全知全能にする問題、により、技術インフラの不足、経済および人的資源の不足のような、発展途上国で長年未解決の課題を悪化させています。これは新種の情報格差、データベースの知性を利用する意思決定の格差です。
§マーケット
ビッグデータは情報管理の専門家の需要が増加しており、Software AG、オラクル、IBM、マイクロソフト、SAP、EMC、HPといった企業は、データ管理と分析だけを専門とするソフトウェア会社に150億ドル以上を費やしています。2010年には、この業界だけで、1000億ドル以上の価値があり、年間約10%で成長していました。これはソフトウェアビジネス全体の約2倍の速さです。
先進国では、データ集約型の技術の利用が増加しています。全世界で携帯電話契約数は、46億であり、10億から20億の人々がインターネットにアクセスしています。1990年から2005年の間に、10億以上の人々が中流層に入り、これは人は裕福になれば文字が読めるようになり、それが情報の増加につながることを意味します。
通信ネットワークを介して情報を交換する世界の実効容量は、1986年に281ペタバイト、1993年に471ペタバイト、2000年には2.2エクサバイト、2007年には65エクサバイトでしたが、インターネット上を流れるトラフィック量は2013年までに毎年667エクサバイトに達すると予測されています。
§アーキテクチャー
2004年、Googleは以下のようなアーキテクチャを使用したプロセスMapReduceに関する論文を発表しました。
MapReduceフレームワークには、膨大な量のデータを処理するため、並列プログラミングモデルおよび関連した実装が含まれます。MapReduceでは、クエリは分割され分散並列ノード間で並列に処理(マップステップ)されます。結果が集められ配信されます(リデュース・ステップ)。フレームワークは成功しましたので、そのアルゴリズムを再現しようとした者もいました。
そこで、MapReduceのフレームワークの実装のひとつがHadoopという名前で、Apacheのオープンソースプロジェクトで採択されました。
MIKE2.0は、情報管理のためのオープン・アプローチです。その方法論は、ビッグ・データを データソースを有用な順列、 相互関係における複雑性、各レコードの削除(あるいは変更)における困難さの側面で処理するものです。
§テクノロジー
DARPAのトポロジーデータ解析プログラム(クラインの壷)大規模なデータ集合の基本的な構造を探っています。
ビッグデータでは、効率的に許容経過時間内に大量のデータを処理する卓越した技術が必要となります。2011年マッキンゼーレポートにおいて 必要な技術は以下が必要と示唆されました。
A / Bテスト、 相関ルールの学習、 統計分類、 データ・クラスタリング、 クラウドソーシング、 データ融合と統合、 アンサンブル学習、 遺伝的アルゴリズム、 機械学習、 自然言語処理、 ニューラルネットワーク、 パターン認識 、 異常検出、 予測モデリング、 回帰分析、 感情分析、 信号処理、 教師あり学習と教師なし学習、 シミュレーション、 時系列解析、 可視化です。
多次元ビッグデータはテンソルとして表現でき、多線部分空間学習のようなテンソル・ベース計算にて効率的に処理できます。さらにビッグデータに適用される技術には、超並列処理(MPP)データベース、 検索ベースのアプリケーション、データマイニンググリッド、分散ファイルシステム、分散データベース、クラウドベースのインフラストラクチャ(アプリケーション、ストレージ、コンピューティング資源)とインターネットが含まれます。
すべてではなく一部のMPPリレーショナルデータベースは、ペタバイトデータを格納および管理する能力を持っています。暗黙的にRDBMSのビッグデータテーブルをロード、監視、バックアップする能力も必要となります。
DARPAのトポロジーデータ解析プログラムにおいて、大規模なデータ集合の基本的な構造を求められ、2008年にその技術はAyasdiという会社の立ち上げで公になりました。
ビッグデータ分析プロセスの専門家は、一般的に遅い共有ストレージを敵視し、ソリッド・ステート・ドライブ(SSD)や、並列処理ノード内部に埋め込??まれた大容量SATAディスクなど、様々な形で直接接続ストレージ(DAS)を好みます。
共有ストレージのアーキテクチャ(SANとNAS)は比較的遅く、複雑で、高価であると認識されます。これらの性質は、システム性能、容易に入手可能、低コストで成長するビッグデータ分析システムと合致しません。
リアルタイムまたはほぼリアルタイムの情報配信は、ビッグデータ分析の定義の特徴の一つです。遅延はいかなる場合でも回避されます。メモリ内データは好まれますが、FC SAN接続で繋がった回転ディスク上のデータは好まれません。分析アプリケーションで必要な規模でのSANのコストは、他のストレージ技術より非常に高いのです。
ビッグデータ分析での共有ストレージには、利点だけでなく欠点がありますが、ビッグデータ分析の実務家は2011年現在それを支持しませんでした。
§研究活動
2012年3月に、ホワイトハウスは6連邦政府省庁および政府機関で構成され2億ドル以上の予算を付与された、「ビッグデータイニシアティブ」を発表しました。
イニシアティブにはカリフォルニア大学バークレー校にあるAMPLabへの、全米科学財団「計算機科学の探検」研究費、5年間の$1千万ドルを含みます。 AMPLabはまた、DARPAと10以上の産業界からの資金提供を受け、交通の混雑の予測、がん対策のような広範囲の課題に挑戦します。
ホワイトハウス・ビッグデータ・イニシアティブはまた、エネルギー省のローレンス・バークレー国立研究所が率いるスケーラブル・データ管理・分析・可視化(SDAV)研究所へ米国エネルギー省から5年間に $25百万ドルの資金提供も含みます。. SDAV研究所は、科学者が省のスーパーコンピュータ上のデータを管理し、可視化するための新しいツールを開発するために6国立研究所と7大学の専門知識を結集することを目指しています。
米国マサチューセッツ州は、2012年5月にマサチューセッツ州ビッグデータイニシアティブを発表し、州政府や民間企業が研究機関の様々な資金を提供しています。マサチューセッツ工科大学 はthe Intel Science and Technology Center for Big Data をMITコンピュータ科学・人工知能研究所で主催し, 政府、民間、研究所の資金と労力を組み合わせています。
欧州委員会は2年間のビッグデータ・プライベート・フォーラムにSeventh Framework Programを通じて資金提供し、企業、教育機関、その他のビッグデータ問題の関係者が参加しています。プロジェクトの目標は、ビッグデータ経済の実装を成功における欧州委員会からの支援行動を導くため、研究と技術革新の面で戦略を定義することです。
このプロジェクトの成果は 次のフレームワークプログラムであるHorizon 2020で利用されます。
IBMは毎年開催される学生のビッグデータ大会、第37回Battle of the Brainsに2013年7月にスポンサーとなりました。初開催のプロ向けの2014ビッグデータ世界選手権は、テキサス州ダラスで開催される予定です。
§批判
ビッグデータパラダイムの批判には、2つの流儀があり、アプローチ自体に疑問を呈するものと、現在の方法に疑問を呈するものがあります。
§ビッグデータパラダイムへの批判
重要な問題は、私たちはビッグデータの典型的なネットワークの特性の出現につながる、基礎実験マイクロプロセスについてはあまり知らないということです。
Snijders、Matzat、Reipsはその批判で、マイクロプロセスレベルで起きていることを全く反映しない数学的性質に関して非常に強い仮定がされていることを指摘しています。マーク・グレアムは ビッグ・データはビッグ・データは仮説の終わりを招くというクリス・アンダーソンの仮定を強く批判し、ビッグ・データはその社会的、経済的、政治的コンテキストにおいて、コンテキストを解釈されなければならないと述べました。
8-9桁の投資を行う会社であっても、供給者と消費者からの情報から何らかの識見を得るために40%未満の従業員が十分に成熟してそれを行うスキルを持っていなければなりません。
ハーバードビジネスレビューの記事によると、識見がない欠点を克服するために、 ビッグデータは、どんなにわかりやすく、あるいは分析されたとしても、大きな決断(ビッグディシジョン)によって補完されなければならないとしています。
ほぼ同じ行で、ビッグデータの分析に基づいた決定はビッグ・データの分析による決断は必然的に「過去に知られたものか、良くても現在のもの」にしかならないと指摘されました。
過去の経験が多数入力されれば、アルゴリズムが過去と同じ事象を予想する可能性があります。将来のシステムの動的性質が変わるならば、過去を使って、将来についてわかることは少しはあるわけです。このために、システムの動的性質、すなわち仮説、を完全に理解することが必要になります。
この批判への応答として、例えば、 エージェントベースモデルのようなコンピュータ・シミュレーションでビッグデータのアプローチを組み合わせることが提案されています。また、このような因子分析やクラスター分析などのデータの潜在構造用のプローブは、通常小さいデータ集合で使用される双方向変量アプローチよりも、分析的アプローチ(クロスタブ)として有用であることが証明されています。
保健学と生物学では、従来の科学的なアプローチは、実験に基づいています。これらのアプローチでは、制限要因は、初期仮説を確認したり、反証することができる関連データです。
現在生命科学では新しい原則が受け入れられています。すなわち、前提となる仮定を持たない大量のデータ(オーミクス)をもつ情報は補足的なものであり、実験に基づく従来のやり方が必要になるわけです。
大規模な方法において、制限要因であるデータを説明するための関連仮説の形成です。その検索ロジックは反転し、帰納法の制限(Glory of Science and Philosophy scandal, C. D. Broad, 1926)が考慮されなければなりません。
消費者プライバシーの提唱者は増加する保存データと個人が特定可能な情報の統合に懸念を示しています。専門家の委員会は、プライバシー保護を実行するための数多くの勧告を行っています。
§ビッグデータ実行の批判
ダナ・ボイドは 科学が代表的な母集団を選ぶという基本的原則を無視し大量のデータ処理にこだわることに懸念を示しました。このやり方は、いずれにしろ偏った結果につながる可能性があります。異種のデータ源(ビッグ・データと見なすかどうかは見解が分かれますが)は分析的な課題だけでなく、運用上の手強い課題がありますが、多くの科学者はこのような統合は最も有望な科学の最先端と主張しています。
もっと勉強したい方は⇒統計学入門セミナー