
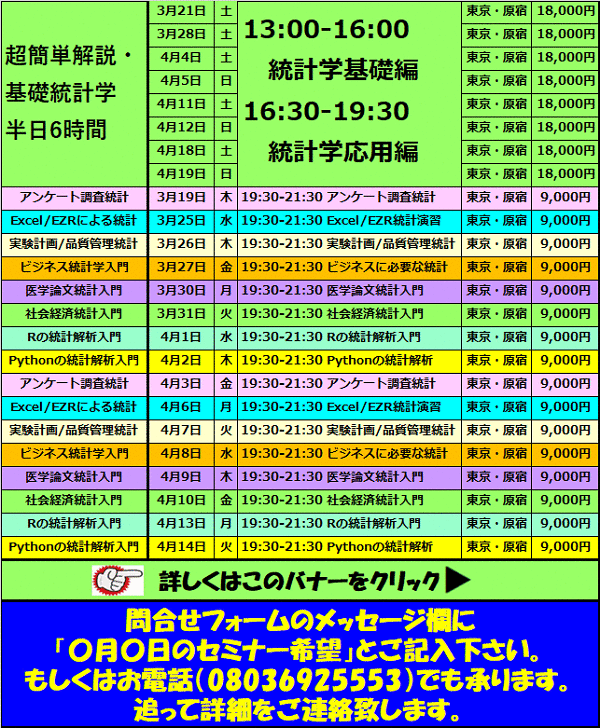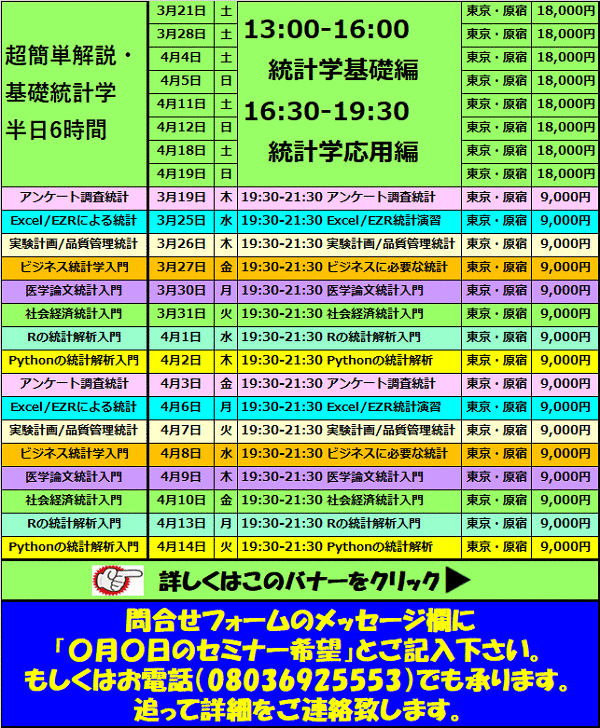
▼▼▼▼▼▼▼▼ ▼▼▼▼▼▼▼▼
お問合せはこちら セミナー詳細こちら
医療統計学における推定と検定
医療統計学、医療経済学、数学のつぼをたとえ話でわかりやすく解説
運営者の20年以上にわたる医療統計学のノウハウを満載
医療統計学における推定と検定

<信頼区間>
標準誤差を実際に計算するときは、先の10人の年齢データの例では標準偏差を標本の大きさの平方根、ここでは√10で割ります。標本が大きいほど、細いつりがねになります。
100個の標本平均は中心極限定理により正規分布をしていますから、この100個中68個の標本平均は、平均値±標準誤差の範囲に入るということになります。標準偏差はデータのばらつきですが、標準誤差はそうではなく、標本平均のばらつきです。標本平均は母平均の推定値ですから、標準誤差が小さいということは、母平均の推定精度が高いということになります。
95%信頼区間は、100個中(68個ではなく)95個入るような範囲です。つまり、平均値±標準誤差の範囲より広くなります。具体的には、標準誤差をt倍します。
つまり平均値±t×標準誤差 が計算式です。標準誤差と同様、この範囲が狭いほど、母平均の推定精度が高いということです。tは2に近い値です。
<t検定>
A群 28歳 30歳 33歳 38歳 40歳 43歳 46歳 49歳 51歳 52歳
B群 20歳 22歳 25歳 30歳 32歳 35歳 38歳 41歳 43歳 44歳
10人のA群と、別の10人のB群(独立2群)で、年齢の差があるかどうかを考えます。
その際に、先ずA群とB群は年齢に差がないと仮定します。
この仮定が成り立つt分布の確率が5%を切る場合、上の仮定は20回に1回すら起こり得ない稀なことであると判断し、上の仮定を棄却しA群とB群は差があるとします。
これが独立2群のt検定です。実際に検定をすると、5.4%となり5%を切らないので、仮定は棄却されず、A群とB群は差があるとはいえない、という結論になります(差がない、という結論でないことに注意)。
ところで、B群はA群の8年前のデータだとした場合はどうでしょう。
この場合は独立2群ではなく、同じ群を8年前と比較するわけですから対応のある2群ということになり、この場合は対応のあるt検定を行います。独立2群に比べると有意差は出やすくなります。
実際この場合、2.7%で5%を切り仮定は棄却され有意となります(A群とB群は差があるという結論です)。
★★統計学目次★★
▼▼▼▼▼▼▼▼ ▼▼▼▼▼▼▼▼
お問合せはこちら セミナー詳細こちら


医療統計学における推定と検定 関連ページ
- 医療統計学の世界へようこそ
- 医療統計学って何?
- 医療統計学において必要な判断
- 医療統計学はなぜ重要か
- 医療統計学はなぜ嫌われるのか
- 医療統計学データのはなし
- 医療統計学における度数分布
- 医療統計学における確率のはなし
- 医療統計学における確率
- 医療統計学における条件付き確率のはなし
- 医療統計学におけるフィッシャーの3原則
- 医療統計学における実験計画法
- 医療統計学における紅茶の実験
- 医療統計学におけるにおける中心極限定理
- 医療統計学における予測
- 医療統計学における全体像を掴む
- 医療統計学における発想の転換
- IT革命と医療統計学
- 埋もれている医療統計学データ
- 医療統計学の意義
- 医療統計学における測定値についての理解
- 医療統計学における平均と標準偏差を知る
- 医療統計学におけるばらつきを説明する
- 医療統計学においてヒストグラムは優れた武器
- 医療統計学における正規分布の面白い話

