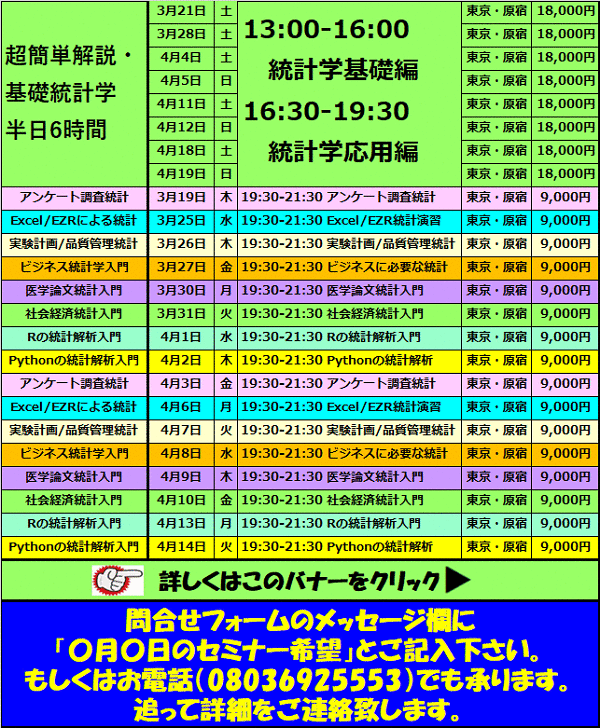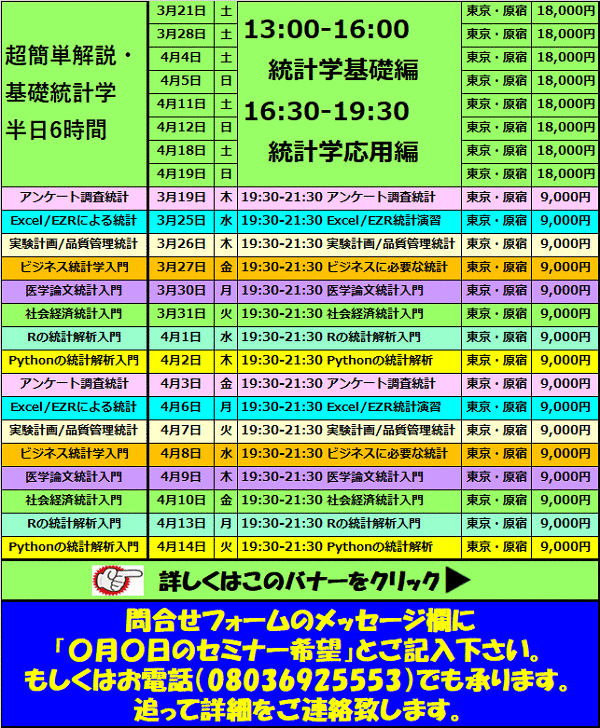
▼▼▼▼▼▼▼▼ ▼▼▼▼▼▼▼▼
お問合せはこちら セミナー詳細こちら
医療統計学:検定に最適なデータ量
医療統計学、医療経済学、数学のつぼをたとえ話でわかりやすく解説
運営者の20年以上にわたる医療統計学のノウハウを満載
検定に最適なデータ量
検定を行うのに最適なデータ量はどのくらいでしょうか?
この問に答えることは難しいことです。
統計家に聞いても十人十色の答えが返ってくるのではないかと思います。
結論的にいうと、データを取る努力を途中で放棄する必要はないと思います。
通常の統計的検定が、データから結論を得る唯一の方法というわけではなく、いろいろな方法があります。
通常の統計的検定は、大量のデータ解析には適していないということが問題なのです。
この原因は、統計的検定のロジックの問題です。
より具体的には、問題が生じる由来は、帰無仮説と対立仮説という2つの仮説の非対称性です。
たとえば、帰無仮説は、母平均がある特定の値に等しいとか、2つの母平均が等しいとか、任意の値をとり得るという意味で無限の可能性をもつ対立仮説に比べると非常に狭い範囲に存在することを主張するものです。
したがって、大量のデータを得ると明らかに対立仮説が正しいことになるのです。
一見ほんのわずかの平均値の差でも、データが大量だと有意になる場合があるのです。
また、統計的仮説の検定のロジック自体も別の考え方があり得るのです。
たとえば、帰無仮説vs対立仮説というおなじみの図式の場合でも、データ数が非常に大きいときは、ベイズ的考え方による検定方式は帰無仮説を採択する傾向があります。
いずれにしても、統計的検定法はデータから自分のもっている研究仮説の真偽を確かめる方法のうちの一つであるという相対的な見方が必要かと思います。
ただし、実験的方法のマニュアルが完備しており、データ数もある程度コンセンサスがある領域では、通常の仮説検定の方式を堅く守っていくということのメリットもあるかもしれません。
このような領域では、よく計画された実験が繰り返されるという通常の統計的検定の前提が成立していると考えるからです。
一方、1万とか10万とかの調査データに対しては、単純な帰無仮説vs対立仮説の図式ではなく、データを多角的に分析して、いろいろな情報をくみとることができます。
もちろん、恣意的な判断におちいらないように注意することが必要です。
また、統計的推論を適用するとしても、大量データの利点を活かしてパラメータが多い階層的で複雑なモデルについて推論し(たとえば共分散構造分析モデル)、因果関係について知見を増やすというような使い方ができます。
もっと勉強したい方は⇒統計学入門セミナー