
���������������� ����������������
���⍇���͂����� �Z�~�i�[�ڍׂ�����
��Ó��v�w�I�_���̓ǂݕ��F���v�I����̃��W�b�N
��Ó��v�w�A��Ìo�ϊw�A���w�̂ڂ����Ƃ��b�ł킩��₷�����
�^�c�҂�20�N�ȏ�ɂ킽���Ó��v�w�̃m�E�n�E��
��Ó��v�w�I�_���̓ǂݕ��F���v�I����̃��W�b�N
�_���Ŏ����ꂽ���ʂ����߂���ɂ́C�ᔻ�I�ᖡ���s�Ȃ��\�͂��t���Ɋ��p���Ȃ���Ȃ�܂���B
��ЂƂ̐}�\��ǂލۂɁC�u���̌��ʂ͂������������Ӗ�����̂��v�ƍl����ׂ��ł��B
�u���ӁI�v�������t�ł��B�l���傫��.�h���I�ŁC�\�����ʌ��ʂƂ����̂͋ɂ߂Ă܂�ŁC��������������������m���̂ق��������Ƒ����̂ł��B
���ʂ���������ۂɂ́C�L�Ӑ��̋ᖡ��C���͒��̗��Ƃ����̃`�F�b�N�𒍈Ӑ[���s�Ȃ�Ȃ���Ȃ�܂���B
���ẮC�傽��m�����L�q�����������\�ƃO���t�����������̘_��������܂����B���݂ł́C�����_�����C���v�I����ɂ���Č��ʂ̓��v�I�L�Ӑ���]������͓̂��R�̂��ƂƂȂ��Ă��܂��B
���v�I���肪�K�v�Ƃ����̂́C���R�̍�p�iplay of chance)���ǂ��ɂł����邩��ł��B
�����̂��߂Ɋ��҂̃O���[�v��I�ԂƂ��⑪�������Ƃ��ɂ́C���R����p���Č��ʂɉe����^����\�����˂ɂ���܂��B
���R�̍�p�̉e����.�T���v�����������Ƃ��ɍł������ł��B
10�l�̐V�������T���v���Ƃ��đI�Ƃ��܂��傤�B
���悻�����͏��̎q�ł��낤�Ɗ����͂�����̂́C���̎q��7�l�ŁC�j�̎q��3�l�����ł������Ƃ��Ă��N�������Ȃ��ł��傤�B
������x�C�T���v����I�Ƃ��C���̎q��4�l�ŁC�j�̎q��6�l�ł����Ă���͂�N�������Ȃ��ł��傤�B
�T���v�����傫����Βj�̎q�Ə��̎q�����悻�������l���ƂȂ邱�Ƃ����҂���܂����A�����ȃT���v���ł͋��R�̍�p�̂����Œj���䂪1��1�ɕ�����邱�Ƃ͂߂����ɂ���܂���B
���R�̍�p�̉e���́C��w�����ł͂ǂ��ɂł������܂��B
�Տ������ɂ�����2�̎��Ö@���r����Ƃ��܂��傤�B ���҂������_����2�̃O���[�v�Ɋ��蓖�Ă܂��B
�����_�����ɂ���āC2�̃O���[�v�Ԃ̌n���I�ȍ��isystematic differences�j�͖h���܂����C���R�ɂ���Đ����鍷�͖h���܂���B
���Ƃ��C�Е��̎��ÃO���[�v�ɏd�a�̊��҂��킸���ɑ������蓖�Ă��Ă��܂��ƁC���ۂɂ�2�̎��Ö@�̊Ԃɂ͍����Ȃ��ɂ�������炸�A�ꌩ.��������悤�Ɍ����Ă��܂����Ƃ�����܂��B
���ہC�Տ������ɂ�����2�̃O���[�v���S�������ł��邱�Ƃ͂قƂ�ǂ��肦���C�O���[�v�Ԃɂ́C���R�ɂ�鏬���ȍ�������̂����ʂł��B
�������C�O���[�v�ԂɁC���R�ɂ����ɑ傫�ȍ������邱�Ƃ͂߂����ɂ���܂���B
���R�̍�p���d�v�ł���̂́A���ꂪ�C�ώ@���ꂽ�������ʂɗ^����e���̑傫���ɂ��܂��B
�����[�����ʂ̂悤�Ɍ����Ă��A���v�I�Ȃ܂��ꂠ����ł������Ƃ������Ƃ��ŏI�I�ɏؖ�����邱�Ƃ��C�Ƃ��ɂ͂���܂��B
���v��@��p���邱�Ƃɂ��C�ώ@���ꂽ���ʂ����R�̍�p�ɂ����̂��ۂ����C�K�^�ɂ����肷�邱�Ƃ��ł��܂��B
���̕��@�̒��S�ɂ́C�m���̊T�O������܂��B
�������܂łȂ�6�ʂ̃T�C�R����U����6�̖ڂ̏o��m����6����1�ł��B
�i�C�M���X�́j���œ����肭�����o��m����140������1�ł��B
�m���́C���鎖�ۂ��ǂ̂��炢�������������Ȍ��ɋL�����@�ł��B
�m���͏����ŕ\�킳��邱�Ƃ������ł��B
���Ƃ���6����1��0.167�ƕ\�킳��܂��B�m���̉��߂͋ɂ߂ĊȒP�ł��B���鎖�ۂ����ɏ����Ȋm�������Ƃ��C���Ƃ���0.0001�̂悤�ɔ��ɏ������Ƃ��C���̎��ۂ������邱�Ƃ͂قƂ�ǂ���܂���B
�m�����傫���Ƃ��C���Ƃ���0.9�̂Ƃ��C���ۂ͔��ɐ����₷���ł��B
�m����0.0��1.0�̊Ԃŕϓ����C0.0�͎��ۂ������Đ����Ȃ����Ƃ��Ӗ����C1.0�͊m���ɐ����邱�Ƃ��Ӗ����܂��B
�l�Ԃ͊F�������ʂ̂�����C���錒�N�Ȑ��l�������ꎀ�ʊm����1.0�ł��B
����C���̐��l���������ʊm����10������1�܂�0.00001��菬�����̂ł��B
�o�X��瀂����Ƃ��������肻�����Ȃ����ۂł��C���܂��ܐ����邩������Ȃ��̂ŁC�m���͊��S�ɂ�0.0�ł͂���܂���B
�������C���肻�����Ȃ����ۂ͂߂����ɋN���Ȃ��̂ŁC�m���͔��ɏ������ł��B
�m���͓��v�I����̊j�ɂ���T�O�ł��B
�m���͂�����p�l�ƌĂ�܂����Cp��probability (�m���j�̗��ł��B
��������@�1000����3�Ƃ����C���Ȃ�܂�Ȏ��ۂ̏ꍇ�C�m����p=0.003�Ə������Ƃ��ł��܂��B
���̊m����p��0.01�Ə������Ƃ�����܂��B���́u���v�L���́u? ��菬�����v���Ӗ����܂��B
����0.003��0.01��菬�����ł�����p=0.003�ł����0.01��菬�����Ȃ�܂��B
�u���v�L�� �͍L���p�����Ă��܂����Ap��0.01�Ƃ����\����p=0.003 �Ƃ����\���������m�ł͂���܂���B
�ߋ��ɂ́C�u���v�L�����g�p���āC�m�������̒l�ɂ܂Ƃ߂ĕ\�����邱�Ƃ����s�������Ƃ�����܂��B
���Ƃ��ł���ʓI�������̂́Cp��0.05�Cp��0.01�Ap��0.001�Ƃ������\���̎d���ł��B���������݂ł́C�������T���l�Ƃ��ĕ\������̂͏��̖��ʎg���Ȃ̂ŁA���m��p�l���������Ƃ��D�܂����Ƃ���Ă��܂��B
���v�I����ł́C��ɂ��v����悤�ȃ��W�b�N��p���܂��B
���̂悤�ȃ��W�b�N��p����̂́A�����������������邽�߂ł���Ǝv���邩������܂��C�����ł͂���܂���B
���̂悤�ȍl������p����̂��C�B��̑Ó��ȕ��@������ł��B
�Տ������ŁC�D��ɍ�������2�̎��Ö@���r���錤�����C��ɂ��Ă݂܂��傤�B
�ŏ��̃X�e�b�v�́A���Ö@�ԂŊώ@���ꂽ�������R�̍�p�̌��ʂ����ɂ�邱�ƁC���Ȃ킿���Ö@�Ԃɐ^�̍����Ȃ��Ƃ���������ݒ肷�邱�Ƃł��B
�����Ȃ��Ƃ������ʂ�]��ł���킯�ł͂���܂���B
�V�������Ö@���]���̎��Ö@�����D��Ă��Ăق����͓̂��R�ł��B�Ƃ͂����C���̃��W�b�N�ł�.���̂悤�ȓW�J�ɂȂ�̂͒v�����Ȃ��̂ł��B
���̃X�e�b�v�́C���v�I�����p���āC�ώ@���ꂽ���̂Ɠ����x�̑傫���̍����C���R�����Ő����邩�ǂ������v�Z���邱�Ƃł��B
����́C���ʂƂ��ē���ꂽ�����C���R�̍�p�̂��߂ɐ����Ă���m��. ���Ȃ킿�Cp�l��^���܂��B
���̒l�����ɏ������i���Ƃ���p��0.001)�Ƃ��ɂ́C���ʂ͋��R�̍�p�̂����Ő������̂ł͂Ȃ����낤�ƌ��_�Â��܂��B
���������āC���̏ꍇ�ɂ�.���Ö@�Ԃɍ����Ȃ��Ƃ������������p���A����̎��Ö@����������̎��Ö@�����{���ɂɗD��Ă���ƌ��_���邱�Ƃ��ł���̂ł��i2�̎��Ö@�Ԃɂ͋��R�ɂ�鍷�ȏ�̍��͂Ȃ��Ƃ��鉼�����C��ʂɋA�������ƌĂт܂��j�B
p�l��.�ώ@���ꂽ���ʂ����R�ɂ����̂��ۂ��f���邽�߂́C���ɕ֗��Ȏw�j�ł��B
p�l���������Ƃ������Ƃ́C���ʂ����R�ɂ����̂ł͂Ȃ��������Ƃ������Ƃ������Ă��܂��B
������p�l���ǂꂾ����������C���ʂ����R�̂����ł͂Ȃ��Ɣ��f���Ă悢�̂������߂Ȃ���Ȃ�܂���B
�����ŁC���ӓI�ł����֗��ȃ��[��������܂��Bp�l��0.05��菬�����i���Ȃ킿p��0.05�j�Ƃ��ɂ͌��ʂ����R�̂����ɂ��Ȃ��Ƃ������[���ł��B
p�l������قǏ������ꍇ�C���ʂ͓��v�I�ɗL�ӂł���ƌ����܂��B
���̜��ӓI�ȃ��[���ip��0.05)�́A�����ȕۏł͂���܂���B
��������v�I������s�Ȃ����Ƃ��܂��傤�B�L�Ӑ������20��s�����тɁC���ς���1��́C�݂������̗L�ӂȌ��ʂ�������Ɨ\���ł��܂��B
�Ȃ��Ȃ�Cp=0.05�Ƃ́C���R�����̂悤�Ȍ��ʂ������N�����m����20��1��Ƃ� �����Ƃ��Ӗ����Ă��邩��ł��B
�܂�C2�̘_���I�ȋA���������܂��B
�@�L�Ӑ�����𑽐��s�Ȃ��Ă��܂��ƁC�݂������̗L�ӂȌ��ʂ邱�ƂɂȂ�܂��B
�Ap�l���������i���Ƃ���p��0.01��p��0.001�j�قǁC���ʂ͋��R�ɂ����̂ł͂Ȃ������Ƃ�����w�����m�M�����Ă܂��B
���R�̉e�������肷�邽�߂�.���v�I����ȊO�́C�����ЂƂ̕��@���M����Ԃł��B
�M����Ԃ́C���v�I��������C�����̏���^���Ă���܂��B
2�̍R��������̗Տ������ŁC����̖�͕��ς���15mmHg���ŏ�������ቺ���������C��������̖�͕��ς���5mmHg�����ቺ�����Ȃ������Ƃ��܂��傤�B
���ς�10mmHg�Ƃ������́C��ۓI�ł͂��邪�C���̍��͋��R�̉e���ɂ���Đ������� ��������܂���B
�����ŏd�v�Ȃ̂́C2�̖�̌��ʂ̍��́C�^�̒l���[���Ɠ������炢�������i���Ȃ킿�����Ȃ��j���ǂ����Ɩ₤���Ƃł��B
���̖₢�ɂ�95%�M����Ԃ�p���ē����邱�Ƃ��ł��܂��B
�M����Ԃ�95%�̊m�M�������āC�^�̒l�����̓����ɂ���ƌ�����͈͂�^���܂��B
�R��������̎�����95%�M����Ԃ�3?17�ł�������C �^�̒l�͍ŏ���3.�ő��17�ł���ƌ����܂��B
�[���͂��̋�Ԃ̊O���Ɉʒu���邽�߁C�[���͐^�̒l�ł͂Ȃ����낤�ƌ��_�Â��邱�Ƃ��ł��܂��B
�����0.05��菬����p�l�邱�� �Ɠ����ł��B
���Ȃ킿���ʂ����v�I�ɗL�ӂł���Ƃ������Ƃł��B
�M����Ԃ͈̔͂������ƍL��������A.���Ƃ���-4?24��������.���߂͈قȂ�܂��B
���͈̔͂̓[�����܂ނ̂Ń[�����^�̒l�ł��肤��̂ł��B
�����.���̏ꍇ�C2�̖�̌��ʂɍ�������Ƃ����G�r�f���X�͂Ȃ��Ƃ������_�ɂȂ�܂��B
�M����Ԃ́C�������@���Տ������ł��낤�ƃR�z�[�g�����ł��낤�Ɖ��ł��낤�ƁC�˂ɓ����悤�ɉ��߂���܂��B
�܂�C�M����Ԃ́C���ʂ��Ȃ��i���Ƃ���2�Q�Ԃɍ����Ȃ��j�Ƃ������������肷�邽�߂ɗp�����܂��B
�����M����Ԃ̓����Ƀ[��������C���ʂ͂Ȃ������ƌ��_�Â��܂��B
�����M����Ԃ͈̔͊O�Ƀ[��������C�����ʂƂ������_�͂��肦�Ȃ������Ȃ̂ŏ��O���܂��B
����͌��ʂ����v�I�ɗL�ӂł���Ƃ������Ƃɓ������̂ł��B
���v�I��������M����Ԃ��D��Ă���̂́A�M����Ԃ́C���ʂ����R�̉e���ɂ����̂��ǂ��������������ł͂Ȃ����R�̍�p���l�����������ŁA�^�̌��ʃT�C�Y�i���ʒl�j�̂Ƃ肤��ŏ��l�ƍő�l�������Ă���邩��ł��B
���v�w100�̊�b ���v�w�Z�~�i�[
�T�C�g�}�b�v
�����ƕ����������́����v�w����Z�~�i�[
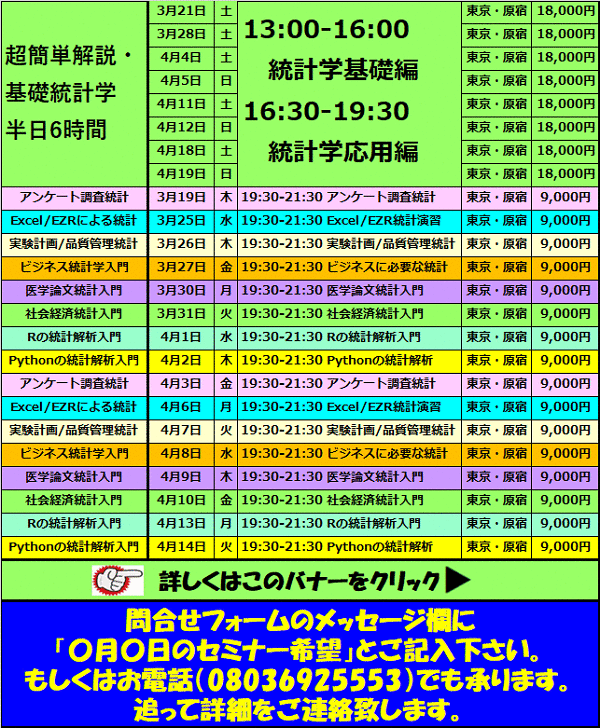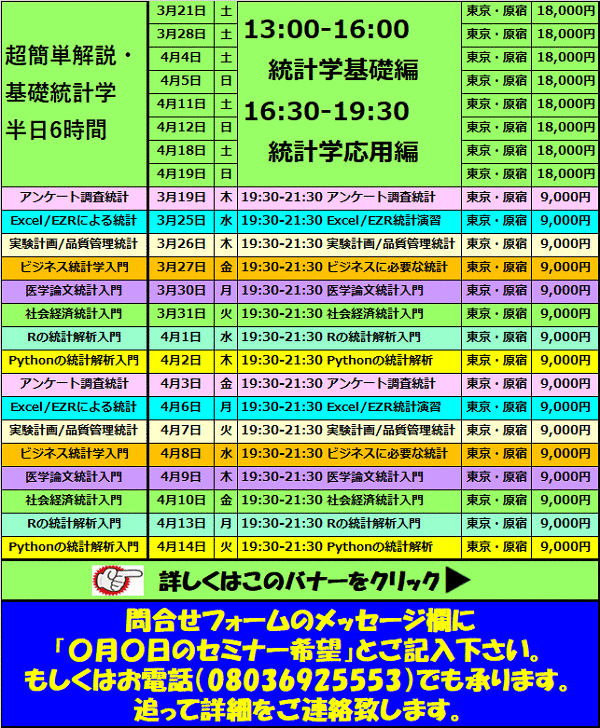


��Ó��v�w�I�_���̓ǂݕ��F���v�I����̃��W�b�N �֘A�y�[�W
- ��Ó��v�w�I�_���̓ǂݕ��F�ᔻ�I�ᖡ�ւ̓���
- ��Ó��v�w�I�_���̓ǂݕ��F�Ȃ��ǂނ��m�ɂ���
- ��Ó��v�w�I�_���̓ǂݕ��F�ǂ�ȏ�K�v�������ڂ��Ă���
- ��Ó��v�w�I�_���̓ǂݕ��F�e�[�}�Ɋ֘A����������������
- ��Ó��v�w�I�_���̓ǂݕ��F�_����ᔻ�I�ɋᖡ����
- ��Ó��v�w�I�_���̓ǂݕ��F���������ǂނׂ��_����
- ��Ó��v�w�I�_���̓ǂݕ��F�u�͂��߂Ɂv�̎�ȖړI
- ��Ó��v�w�I�_���̓ǂݕ��F�ǂ̂悤�Ɍ������s�Ȃ�ꂽ��
- ��Ó��v�w�I�_���̓ǂݕ��F�������������̂�
- ��Ó��v�w�I�_���̓ǂݕ��F�m���̈Ӌ`�͉���
- ��Ó��v�w�I�_���̓ǂݕ��F�������@����������
- ��Ó��v�w�I�_���̓ǂݕ��F�T�[�x�C�i���������j
- ��Ó��v�w�I�_���̓ǂݕ��F�R�z�[�g����
- ��Ó��v�w�I�_���̓ǂݕ��F�Տ�����
- ��Ó��v�w�I�_���̓ǂݕ��F�P�[�X�R���m���[������
- ��Ó��v�w�I�_���̓ǂݕ��F���̗͂��Ƃ���
- ��Ó��v�w�I�_���̓ǂݕ��F��Ɨ���
- ��Ó��v�w�I�_���̓ǂݕ��F�o�C�A�X�ƌ�
- ��Ó��v�w�I�_���̓ǂݕ��F�`�F�b�N���X�g
- ��Ó��v�w�I�_���̓ǂݕ��F���ׂ̏d�v��
- ��Ó��v�w�I�_���̓ǂݕ��F�ŗǁE�ň��E���肦�����ȃP�[�X
- ��Ó��v�w�I�_���̓ǂݕ��F�����_���ɂ��Ė����ׂ��₢
- ��Ó��v�w�I�_���̓ǂݕ��F�����_���ɂ��Ė����ׂ��₢2
- ��Ó��v�w�I�_���̓ǂݕ��F�T�[�x�C��ᔻ�I�ɋᖡ����
- ��Ó��v�w�I�_���̓ǂݕ��F�I���o�C�A�X�͂ǂ̂悤�ɐ����Ă��邩
- ��Ó��v�w�I�_���̓ǂݕ��F�R�z�[�g�����̋ᖡ
- ��Ó��v�w�I�_���̓ǂݕ��F���I/����͐��m�ɑ��肳��Ă��邩
- ��Ó��v�w�I�_���̓ǂݕ��F�Տ������̋ᖡ
- ��Ó��v�w�I�_���̓ǂݕ��F�P�[�X�R���g���[�������̖{��
- ��Ó��v�w�I�_���̓ǂݕ��F�P�[�X�R���g���[�������̖ړI

